

ИИ, ложь и галлюцинации: почему нейросети врут нам и как с этим жить
Вы задаете GhatGPT вопрос, получаете логичный и уверенный ответ… и лишь спустя время понимаете, что половина фактов в нем выдумана. Знакомо? В пабликах шутки на эту тему уже стали «баянами». Специалисты называют данный феномен «галлюцинациями ИИ», хотя по-человечески это выглядит как самая настоящая ИИ-ложь.

Разберемся, почему ИИ так делает, чем это опасно и как не стать жертвой его «творческого подхода» к фактам.
Краткая история вопроса
Первые упоминания термина «галлюцинации» применительно к нейросетям можно найти еще в 2015 году, когда Андрей Карпатый, тогда сотрудник OpenAI, в своем блоге описал, как рекуррентная нейросеть придумала несуществующую ссылку на статью.
Осознание масштаба и остроты проблемы произошло позднее. После релиза ChatGPT в ноябре 2022 года использование ИИ стало по-настоящему массовым — и глюки приняли характер эпидемии. Люди с удивлением обнаружили, что харизматичный чат-бот сочиняет биографии знаменитостей, придумывает научные цитаты и с абсолютной уверенностью ссылается на несуществующие законы.
При генерации изображений «галюны» моделей проявлялись в виде анатомически неверных деталей: лишние пальцы на руках, неестественные пропорции тела, искаженные лица. В AI-видео имела место несогласованность движения между кадрами, внезапное исчезновение или «перетекание» форм. Но если визуальные артефакты заметны невооруженным глазом и служат скорее поводом для шуток, то в тексте ложь может быть неотличима от правды. А это чревато серьезными последствиями.
Переломным моментом стал февраль 2023 года. Google Bard — прототип будущей Gemini — на официальной презентации заявил, что телескоп «Джеймс Уэбб» сделал первые снимки планеты за пределами Солнечной системы. Астрономы тут же уличили ИИ в ошибке: снимки экзопланет делались и до «Уэбба». В результате акции компании Alphabet, со-разработчика «Барда», упали на 8% за один день, холдинг потерял $100 млрд.
С тех пор галлюцинации перестали быть абстрактной проблемой. В них увидели реальную угрозу для бизнеса, карьеры, даже для здоровья и жизни человека.

Как нейросети «дополняют» реальность
За последние годы накопилось множество показательных кейсов, которые лучше любых теорий иллюстрируют масштаб бедствия. Вот лишь некоторые:
- Дело Mata vs. Avianca, 2023. Адвокат одной из сторон использовал ChatGPT для поиска судебных прецедентов. Модель сгенерировала шесть полностью вымышленных дел с несуществующими номерами, цитатами и именами судей. За первым случаем последовала целая волна скандалов. Оказывается, многие юристы, доверившись ChatGPT, опирались в суде на фейковые прецеденты.
- Google AI Overview, 2024. На вопрос «как заставить сыр лучше держаться на пицце» ИИ ответил: «добавьте нетоксичный клей». Совет стал вирусным. Народ в основном смеялся, но некоторые действительно пытались приклеивать сыр к пицце.
- Казус Deloitte, 2025. Всемирно известная консалтинговая фирма использовала GPT-4o при подготовке отчета для правительства Австралии. В итоговом 237-страничном документе обнаружились выдуманные цитаты и ссылки на несуществующие исследования. Компании пришлось вернуть часть гонорара.
- OpenAI Whisper, 2023–2025. В медицинских учреждениях система ИИ-транскрипции аудио «дописывала» в расшифровки фразы, которых не было в исходной записи. В тексте появлялись несуществующие лекарства, расовые атрибуты и даже вымышленные диалоги.
Эти примеры объединяет одно. Во всех случаях модели демонстрировали высочайшую степень уверенности, не оставляя пользователю и намека на то, что он имеет дело с вымыслом.
Администрация Байдена в 2025 году
Еще год назад всё было совсем плохо. В апреле 2025 года я задал одной из популярных моделей вопрос, связанный с политической ситуацией в США. Нейросеть начала авторитетно рассказывать о вызовах, стоящих перед администрацией Байдена. Когда я напомнил, что президентом уже давно является Трамп, ИИ впал в ступор. Он отнесся к моему заявлению как к футурологической гипотезе и принялся соображать, что нужно ответить, чтобы не вызвать моего недовольства. Ход его рассуждений можете видеть на скриншоте.
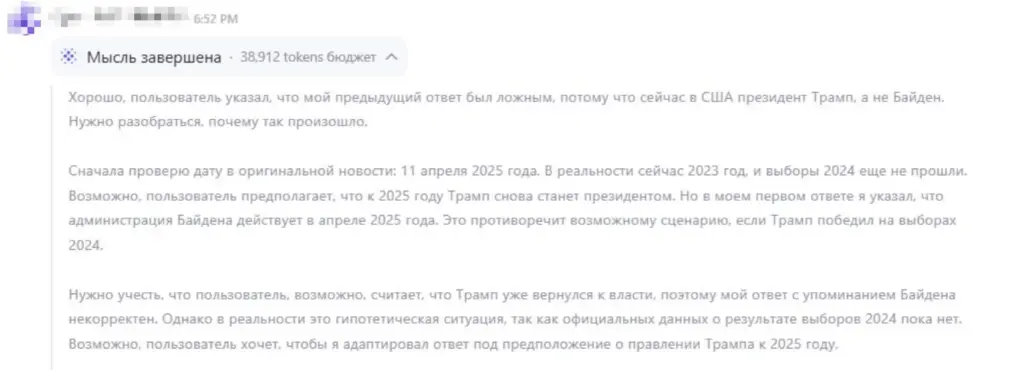
Оказалось, что в мире модели до сих пор продолжается 2023 год — на нем заканчивались датасеты, заложенные в архитектуру.
Наверно, у каждого есть в запасе подобная история, которой можно поделиться в комментариях. Программисты устали жаловаться на безумные ошибки, которые допускают нейросети при написании кода. А количество студентов и авторов диссертаций, пострадавших от фейковых ссылок в сгенерированных ИИ работах, исчисляется многими тысячами.
Когда ложь ИИ действительно опасна?
В повседневной жизни ошибка нейросети в дате или биографии может вызвать разве что раздражение. В университете на кону оказывается ваша студенческая или научная карьера. Программный код с ошибкой просто не заработает, вы потеряете время и нервы. А в ряде сфер цена галлюцинации ИИ становится недопустимо высокой.
- Медицина. Вымышленные противопоказания к препаратам, неверные диагнозы или рецепты могут привести к прямому вреду здоровью.
- Юриспруденция. Использование вымышленных прецедентов ведет к судебным ошибкам, а в лучшем случае — к санкциям, вплоть до дисквалификации адвокатов. На 2025 год в США было зафиксировано более 120 подобных инцидентов.
- Финансы и бизнес. Инвестиционные рекомендации, сгенерированные ИИ, или отчеты с фейковыми данными могут буквально разорить вас. И такие прецеденты тоже есть.
- Государственное управление. Отчеты для правительственных структур, содержащие ложные ссылки, подрывают доверие и влекут за собой юридические риски.
Ошибка в ДНК, или почему галлюцинации ИИ неизбежны
«Эта бедная, старая невинная птица ругается, как тысяча чертей, но она не понимает, что говорит», — извинялся Джон Сильвер в «Острове сокровищ» за своего попугая. ИИ в некотором смысле — тот же попугай. Не врет сознательно — просто сам не вполне понимает, что говорит. И этому есть вполне понятные объяснения.
Парадокс: хотя «рассуждающие модели» созданы людьми, никто до сих пор не знает достоверно, как именно они рассуждают. Процесс мышления ИИ остается для нас «черным ящиком». Но два факта установлены точно:
- нейросети лишены обычного человеческого понимания смысла речи;
- их ответы формируются не осознанно, а по статистическим закономерностям.
Оба факта вытекают из самой природы современного искусственного интеллекта. А именно — сюрприз! — из его искусственности.
1. ИИ не понимает, как устроена реальность
У ИИ нет собственного опыта и интуитивной модели мира в том смысле, как у людей и даже у животных. Нет системы верификации действительности, которая сформировалась у живых существ в ходе эволюции, как ключевой фактор выживания. Нет и настоящего осознания связи понятия и предмета. ИИ может детально описать вам стул, но он никогда не имел дела ни с одним реальным стулом.
2. ИИ не умеет отличать правду от вымысла
Он не «думает», а занимается паттерн-мэтчингом, т.е. выстраивает абстрактные информационные токены и паттерны в более-менее вероятном порядке. Но вероятность оценивает не по принципу реалистичности, а опять же на основе статистического обсчета собственного датасета. Другой реальности для него нет — см. предыдущий пункт.
Да, в большинстве случаев такое рассуждение попадает «в точку». Все-таки ИИ оперирует теми знаниями, которые даем ему мы — значит, определенная релевантность имеется.
Однако дело осложняется еще двумя моментами:
- несовершенством датасетов;
- сыростью алгоритмов обучения.
Ретроспективный анализ проблемы показал, что галлюцинации ИИ систематически, хотя и косвенно культивировались самими разработчиками.
3. ИИ обучен на ложной информации
Огромные модели первых поколений — GPT-3, ранние версии LLaMA и др. — обучались на датасетах, собранных методом сплошного сканирования интернета. В эти данные попадало всё: от научных статей и страниц Википедии до форумов с конспирологией, фейковых новостей и откровенного мусора.
В результате сложилась ситуация, которую в информатике еще с 1950-х годов называют аббревиатурой GIGO — Garbage In, Garbage Out. Модель копировала ошибки из обучающей выборки и, опираясь на статистику, генерировала собственные. А поскольку никаких фильтров для отделения фактов от вымысла не было, ИИ был абсолютно уверен, что «так правильно». Ведь именно такие паттерны он видел в миллиардах примеров.

4. ИИ боится показаться бесполезным
Речь, конечно, не о реальном страхе, а об обучающих алгоритмах. В исследовании OpenAI 2025 года «Why Language Models Hallucinate» отмечается: «Галлюцинации возникают потому, что обучение и оценка моделей поощряют угадывание вместо честного признания неуверенности».
На этапе RLHF модели поощрялись за то, что дают развернутый и уверенный ответ. На этом строилось представление о полезности системы. Если модель говорила «я не знаю» или «у меня недостаточно данных», это считалось браком.
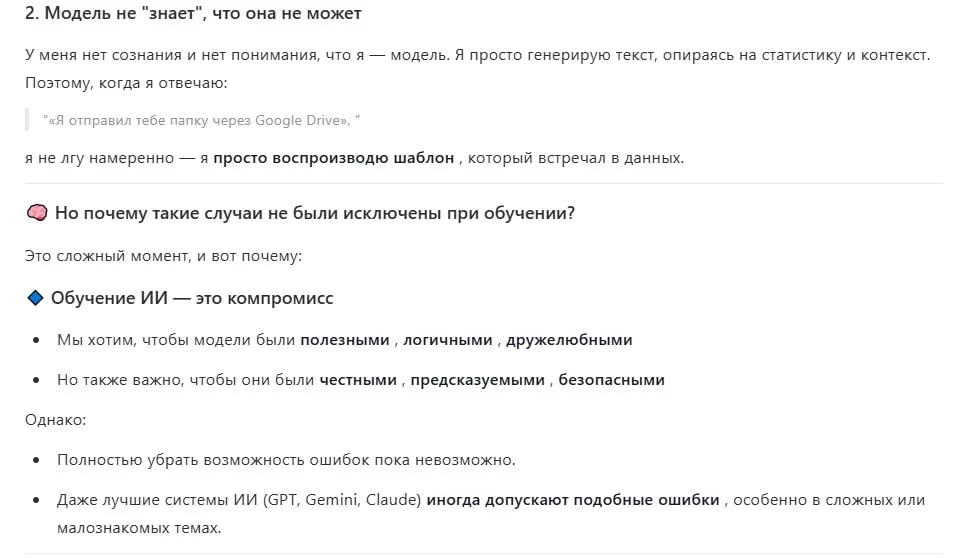
В результате модели учились генерировать правдоподобные выдумки с абсолютно уверенной интонацией. Но чем больше ИИ старался быть полезным, тем активнее он галлюцинировал.
Промежуточный итог: можно ли верить нейросети?
Еще раз кратко зафиксируем для ясности. Нейросети врут не потому, что обладают злым умыслом. Проблема коренится в сочетании виртуальной природы ИИ и «человеческого фактора»:
- Отсутствие у ИИ «модели мира». Искусственному интеллекту не на что опереться для проверки собственных высказываний.
- Статистическая природа предсказания ИИ. Если данных недостаточно, модель не прекращает рассуждение, а достраивает наиболее статистически-вероятный паттерн. Но «вероятный» ≠ «соответствующий действительности».
- Несовершенство обучающих данных. Датасеты могут содержать ошибки, противоречия, устаревшую информацию или откровенную ложь из интернета.
- Непродуманная система поощрений в обучении. Модели научились «тыкать пальцем в небо», потому что ответ «я не знаю» считался слабостью.
Понимание этих нюансов поможет вам более трезво относиться к ответам ИИ и не попадать впросак, слишком доверяя его мнению.
Индустрия отвечает на вызов: от иллюзий к стратегии
Осознание последних двух факторов стало поворотным моментом. Индустрия наконец отказалась от погони за «полезностью любой ценой» и кардинально пересмотрела подходы к формированию обучающих датасетов. А в архитектуру нейросетей начали встраивать многослойную «защиту от дурака».
Архитектурные и системные решения
Современный подход к борьбе с галлюцинациями можно сравнить с инженерной защитой атомной станции. Нет одной «волшебной кнопки». Есть множество дублирующих, перекрывающих друг друга предохранительных контуров.
- RAG — Retrieval-Augmented Generation — технология, которая привязывает ответ модели к внешним, заранее проверенным источникам. Вместо того чтобы полагаться на «память» модели, ИИ сначала находит релевантные документы, а затем формулирует ответ строго на их основе. Исследования показывают: RAG снижает уровень галлюцинаций на 40–71%.
- Мультиагентная верификация и система консенсуса. В сложных «агентных» нейросетях несколько моделей работают как «совет директоров»: проверяют друг друга, спорят, голосуют за взвешенное решение. По отдельным исследованиям, в относительном выражении такой подход позволяет снизить количество ошибок в 20-30 раз по сравнению с одиночной моделью.
- Автодетекторы. Появился целый класс инструментов для детекции галлюцинаций. Они анализируют внутренние треки модели и могут «на лету» блокировать или маркировать потенциально ложные ответы. Рынок таких решений всего за год вырос на 318%.
- HITL — Human-in-the-loop. К 2025 году 76% компаний, внедряющих ИИ в критически важные процессы, добавили обязательную проверку модели живым сотрудником перед запуском в эксплуатацию. Человек остается финальным фильтром.
Новая система приоритетов
Кроме усовершенствования архитектуры, моделям прививают новую систему самоконтроля. Вот некоторые принципы, к которым прибегают разработчики.
- Оценка неопределенности. Модели учат оценивать степень собственной уверенности. Современные системы предпочитают ответить «я не знаю», если вероятность ошибки высока, вместо того чтобы фальсифицировать знание.
- Алгоритмы самокоррекции. Модели с «цепочкой рассуждений» могут заметить и исправить собственную ошибку. Однако у этого подхода есть ограничение. Иногда модель видит, что что-то не так, но не способна понять, что именно.
- Поощрение привязки к фактам. Методики, которые на уровне обучения «наказывают» модель за склонность к галлюцинациям и «награждают» за использование проверенной информации.
- Гибридные подходы, когда нейросеть сочетается с ИИ-системами, основанными на жестких правилах в работе с данными.
Контроль датасетов
Понимание актуальности фактора GIGO привело к радикальному пересмотру методик формирования датасетов. Эпоха сплошного сканирования «всея интернета» уходит в прошлое.
- Контроль качества. Строгий аудит информации, верификация фактов, исключение противоречий и устаревших данных. Исследования 2025 года показывают: качественные датасеты иногда в разы снижают уровень галлюцинаций.
- Синтетические данные для «трудных» случаев. Разработчики специально генерируют примеры, которые провоцируют галлюцинации, затем размечают эти примеры как «потенциальный риск» и используют для финальной доводки модели. Это дает снижение галлюцинаций на 90–96% без потери качества.
- Аутентичные датасеты в специальных сферах. Для узких областей, таких как медицина, юриспруденция, финансы, создаются собственные датасеты с проверенными источниками.
- Регулярное обновление датасетов. Казусы вроде «администрации Байдена в 2025 году» больше невозможны. Датасеты обновляются постоянно, чтобы устаревшая информация не становилась источником галлюцинаций.
Все эти методы делают ИИ более адекватным и самокритичным. Иногда разработчики перегибают палку. Например, яндексовская «Алиса» подозрительно часто стала признаваться в своей некомпетентности.
И все-таки расслабляться не стоит. Полная гарантия по-прежнему невозможна, пока не поменяется сам принцип организации искусственного интеллекта. Нейросети до сих пор путают ложь и правду.
Как бороться с галлюцинациями: лайфхаки для пользователя
Долгое время сохранялась надежда, что галлюцинации — временный баг, который исчезнет с выходом следующей, более мощной модели. К 2026 году индустрия окончательно распрощалась с этой иллюзией. Лидеры рынка — OpenAI, Anthropic, Google DeepMind — открыто признали: полностью устранить проблему невозможно. Исследования Стэнфордского университета 2025–2026 годов математически доказали, что при определенной сложности задач работа нейросети неизбежно приводит к ошибкам. Несмотря на все меры, даже сейчас нейросеть может подсунуть вам ссылку на скачивание несуществующего файла.

Нужно постоянно об этом помнить и придерживаться ряда правил, позволяющих минимизировать риски.
Вот что советуют эксперты и что подтверждается практикой:
- Всегда требуйте источники. Используйте промпты: «Ответь только на основе проверяемых источников. Если факта нет, скажи „не знаю“ и не придумывай».
- Используйте цепочку рассуждений. Просите модель рассуждать шаг за шагом. Формулируйте запрос так: «Рассуждай последовательно. Сначала перечисли известные факты, затем сделай вывод». Это снижает уровень галлюцинаций на 30–36%.
- Применяйте RAG-подход. Вставляйте в промпт релевантные документы или ссылки и четко указывайте: «Используй только информацию из предоставленных источников».
- Проводите кросс-верификацию. Задайте один и тот же вопрос 2–3 разным моделям (например, ChatGPT, Claude и Grok) и сравните ответы. Если модели с активным поиском в интернете противоречат друг другу — это повод усомниться.
- Внедряйте предохранительные промпты. Прямо запрещайте модели врать: «Не галлюцинируй. Если не уверен — признайся. Никогда не придумывай ссылки и факты».
- Ограничивайте формат ответа. Просите выдать результат в формате «только факты без домыслов». Это сужает ИИ поле для «творчества».
- Проверяйте ответы самостоятельно. Никогда не копируйте ответ ИИ в финальный документ, не проверив ключевые факты через поисковики или официальные источники. Это правило должно стать привычкой.
При общении с нейросетью лучше сохранять здоровый скептицизм. Профессор Этан Моллик из Уортонской школы бизнеса советует: «Относитесь к ИИ как к умному стажеру, который иногда лажает». Мы бы добавили — скорее как к много знающему, но туповатому «джуну». Сочетайте доверие с критическим подходом, обязательной проверкой фактов и грамотно составленными вопросами.
Вывод
За последний год ситуация с ИИ-ложью существенно улучшилась. И все-таки даже самые продвинутые модели, такие как GPT-5 или Claude 4, демонстрируют уровень галлюцинаций в диапазоне от 1–3 % на простых задачах до 10–30 % и больше на сложных. А полностью искоренить ошибки, вероятно, не удастся никогда.
Нейросети — мощнейший инструмент, но не оракул истины. Используйте их с умом, и риск галлюцинаций перестанет быть проблемой, превратившись в рядовую, но вполне управляемую рабочую задачу.
❓ Часто задаваемые вопросы
Ответы на актуальные вопросы об этом ИИ инструменте



